THE education site for computer science and ICT
3. Pipelining
Imagine that three people working in a busy cafe want to make thirty cups of tea as fast as possible. Making a cup of tea involves three steps. First pour the tea, add sugar, add milk.

A very slow way of doing it would be for the first person to pour tea into every cup whilst the others are just watching. Then the second person adds all the sugars and the third finally adds the milk. This means two people are idle all the time.
A much quicker way is to have a 'production line' where the first person pours tea into a cup then passes it to the second person, they add sugar and pass it on to the third who adds milk. This means no-one is idle and production has improved threefold.
This production line method is called 'pipelining'.
The CPU also uses pipelining to improve performance. It can do so because the basic step of handling an instruction is the Fetch-Decode-Execute cycle which is the equivalent of those three people making tea.
The diagram below shows the idea of pipelining in a CPU
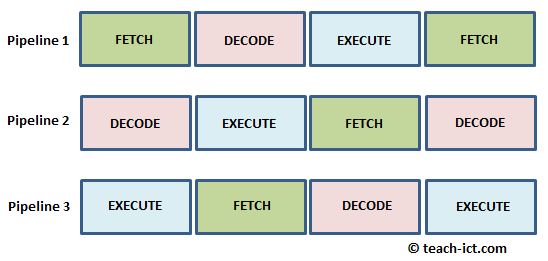
When Pipeline 1 is doing a 'Fetch', Pipeline 2 is doing a 'Decode' on the previous instruction and Pipeline 3 is executing the instruction before that. The three pipelines in the diagram are running at maximum efficiency because they are always full. This is an example of parallel processing.
However, most programs have branches, meaning they jump to out-of-sequence instructions. A pipeline controller has to try and predict the jump in order to keep the pipeline full. This is called 'predictive pipelining'. If the controller gets it wrong, then the pipelines have to be emptied (flushed) and performance is degraded.
So the effectiveness of pipelining depends to some extent on the actual program being run.
Here is a concise definition of pipelining:
Click on this link: CPU pipelining