THE education site for computer science and ICT
3. Lexical Analysis - Lexemes
Lexical analysis is the first stage of compilation.
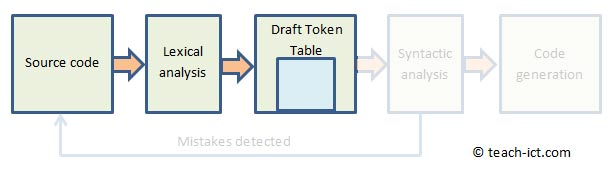
Source code is written by programmers using ASCII characters. During lexical analysis, the compiler breaks down this stream of ASCII characters into its component parts, called "lexemes".
A lexeme is the smallest unit of language. Lexemes cannot be broken down further without losing meaning.
The compiler scans the source code character by character looking for keywords that it recognises from its lexicon. These are immediately labelled as lexemes, since they cannot be broken down without losing their meaning. e.g. it may find keywords such as IF, WHILE, FOR, END and so on.
After the compiler finds the keywords, it tries connecting together the characters between the keywords to form new lexemes. It does this by looking for a character that separates one item from the next - typically this separator is a space. For example
print x
The space character between the the 't' and the 'x' tells the analyser to treat 'print' as a separate item to 'x'.
What it is doing is picking up identifiers - names for procedures, variables and constants.
Exceptions
After the analyser has separated all the items, it then goes through and removes all redundant characters such as tabs and white space. Almost all compilers ignore whitespace (with the exception of Python) and remove it from the code during lexical analysis.
Secondly, source code often contains comments. Comments are meant to be used to explain the code to other programmers who might read it. The comments have no purpose within the program.
The start of a comment is marked using comment symbols (often two slashes //). Anything between the comment symbols and the end-of-line character is ignored by the compiler and so is removed during lexical analysis.
Challenge see if you can find out one extra fact on this topic that we haven't already told you
Click on this link: What is lexical analysis